セルフホスト可能なCコンパイラを書く
最近、コンパイラを書くことが流行っているようだ。流行に乗ってやってみたらいろいろな知見が得られたので紹介したい。
コンパイラを書くと一口に言ってもいろいろなスコープがある。ここではC言語を用いてCコンパイラを書くことを選択した。C言語は言語仕様的にコンパクトで広く知られている。また、ツールとしてのCコンパイラも普及している。その場合、自分が書いたCコンパイラで、自分が書いたCコンパイラのソースコードをコンパイルすることが原理的には可能だ。これをセルフホストという。ひとつの到達目標として非常に興味深い。
当初は冬の間に終わらせる予定だったのだが春まで伸びてしまった。しかし、春になっても寒かったり雨で家に居る日が多く、アウトドアシーズンまでに目標のセルフホストを達成することができた。
昔、Cのインタプリタを書いたことがあったが、コンパイラを書くのは、はじめてである。時代も進んで開発手法が変わったり、コンパイラ特有の技法があったり、いろいろと学びがあった。
リソース
-
https://github.com/rui314/9cc シンプルに書かれたCコンパイラ。最初期のコミットからログが残っているので、最初は写経的に、開発過程をトレースするところから始めた。
-
低レイヤを知りたい人のためのCコンパイラ作成入門 上記9ccの作者が書いているテキスト。内容的には過去のコンパイラ作成の経験を踏まえて、さらにアップデートされていてわかりやすい。
-
コンパイラ―原理・技法・ツール ドラゴンブックとして知られる、コンパイラ関係の教科書。もちろん、私は読み始めたけど完走できなかった。しかし、それ以外のもっと薄いテキストには何冊かトライして構文解析のところは理解できていると思っている。
-
実用Cプログラミング 昔の本で今は手に入りにくいが、思い入れがあるのでリストアップ。この本の中でCのインタプリタを実装している。構文解析は手書きの再帰下降。インタプリタなのでコード生成関係のところは解説されていない。しかし、プログラミング初心者のころにインタプリタの実装にはじめて触れて「自分でも作れるんだ」と思った。そう、作れるのだ。
これ以降、上のドラゴンブックなどを初め、コンパイラ技法の本は何冊か読んだ。この時はyaccなどのパーサジェネレータ、プッシュダウン・オートマトンが興味の中心だった。今回は初心にかえって手書きの再帰降順パーサだ。パーサは軽くすませ、主な関心はコード生成(ABIやBB、SSA)になる。
開発手法
9ccの作者が主張している開発方法はとても興味深い。実際にやってみて、その強力さを実感できた。一般的な開発手法として、どんなソフトウェア開発にも適用可能である。要点を紹介しよう。
非常に簡単なところから始め、つねに動く状態を保つ
フォーマルな開発手法では、仕様が会議などで定められ、仕様書ができたら開発が始まる。それは間違いだ。プログラムの機能や仕様は実装と密接に関係する。どんなに優秀なプログラマでも実装せずに仕様を確定すれば落とし穴や見落としがあるものだ。
拡張に拡張をかさねれば、スパゲッティでメンテナンス不能なプログラムになる恐れがある。しかし、機能を拡張していくときに、パッチ当てではなくその時点で必要な構造化設計・抽象化を随時進めればスパゲッテイになることはない。また、モジュール化、リファクタリングをするのに絶対必要なツールが自動化されたテストだ。つまり、拡張したらメンテナス不能になるのはテストを支えとしたリファクタリングが出来ないから。短く言えば「テストがないから」。
最初は定数を出力するだけのコンパイラを作る。それが電卓レベルの式をコンパイルできるコンパイラになり、条件分岐・関数呼び出しなど機能が追加され、最終的には自分自身をコンパイルできるようになる。途中の段階は、機能が少ないC言語に似たコンパイラだが、その範囲でちゃんとコンパイラとして動作してその範囲のテストに通る、ということが最重要ポイントである。
自動化されたテスト
現代の若者は、自動化されたテストは当然のものだと考えるだろう。私が最初に自動化テストに触れたのは1995年ごろのPerlコミュニティだ。当時PerlはPerl 4からPerl 5変わろうとしていた時代だった。Perl5ではモジュールが導入され、モジュールのリポジトリであるCPAN登録するためには自動化されたユニットテストが求められたのだ。
そこから20年、いまでは自動化されたユニットテストが当たり前だ。導入されていないのは私の勤務先ぐらいなものだろう。
-
テストが自動化されていない。→テストは出荷前のリソースを大量投入した状態でしか行われないだろう。そして、テスト漏れと大量のバグが出る。開発者がテストを書き、それをもとに開発するしか、バグは防げない。納期に追われたそのようなテストは、パスすることが目的となり、ザルで無意味なものになることが多い。
-
テストを書くヒマがない。ドキュメントを書くヒマがない。→テストは実行可能な仕様書であり、自然言語よりも明確で完結だ。最近の言語では「Docテスト」が導入されている。APIの動作をテストコードとしてインラインドキュメント化し、そのドキュメント中のコードが自動実行されるのだ。
-
テストの書き方がよくわからない。→テストツールを導入すると学習コストがかかる。Rustなどの現代的な言語ではテストが言語仕様に含まれているので迷いはないはずだ。Cなどの古い言語でテストを実行するにはノウハウが必要だが、まずはカバレッジにこだわらず、とにかく自動実行することを考えよう。CppUTestは、機能は少ないが移植性は良く、良い選択しだと思う。テストが書ける=入出力が明確になっている、ということでもある。
-
テストをパスしているはずなのにバグが出た。→バグを再現するための最小構成のテストを書こう。最小構成のテストはシンプルなので、製品本体のコードをデバッグするよりもデバッグ時間の短縮にも役立つ。一度書いたテストは自動実行され、エンバグ・デグレを防ぐ。やってみるとわかるが、一箇所を修正したら他のテストが落ちるというデグレは、しばしば生じる。過去のバグ修正の蓄積である自動化テストが無ければ、どうやってデグレを防ぐというのだろうか。
-
それと同時に自動化されたビルドも大事。make一発、Makefileが嫌いなら、代替となるビルドシステムやスクリプトでビルドできるのが望ましい。IDEのビルドボタンではIDEの微妙な設定の影響が入ってしまう恐れがある。
最初は正常系のみ
通常のプログラムではAPIを呼んだ時は返り値をチェックし、エラーならば対処しなければならない。しかし、コンパイラというプログラムの特性上、入力がエラーだったらそれ以上のコンパイルは継続できないので、異常終了するのみだ。わかりやすいエラーメッセージが出せればなお良い(最近のコンパイラはこの方面の進歩が著しい)。
メモリ確保におけるfreeしない、という設計も、コンパイラではうまくいく。
当然、ユーザとのインタラクティブな操作を伴うGUIプログラムやサーバプログラムは、きちんとエラーチェックを行わなければならない。
Gitへのこまめなコミット
これも現代では当然だろう。開発していると、どうにもこうにもうまく行かなくなることは良くある。そのときに、むかし動いていたところまでサクッと戻れることは、とても安心できる。
そういった変更履歴をきちんとトレースして、バグが出た時にいつでも任意の地点に戻れるようにするためにも、Gitのようなツールを活用することは必要だ。ファイルの先頭に変更ログをコメントしておくような粗さでは、後からの役に立たない。変更履歴はGitが管理するものでファイルコメントが管理するものではない。現代ではGitにチェックインされていないソースコードはありえないのだから、適材適所でいこう。
セルフホスト
通常、自分で書いたコンパイラのコードは、gccでコンパイルされる。このコンパイラは通常、stage1コンパイラと呼ばれる。当然、stage1コンパイラはテストコード(C言語)を正しくコンパイルして、できた実行ファイルは正常に実行されなければならない。これは stage1テストと呼ばれる。stage1コンパイラは、アルゴリズムは自作、ただしgccでコード生成されている。
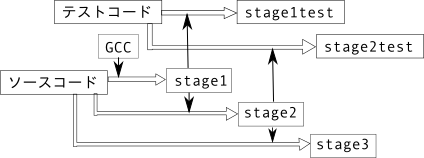
stage1コンパイラはCコンパイラなので、テスト(stage1test)だけでなく、自分自身のコンパイラソースコードをコンパイルすることができる。これをセルフホストと言う。そうしてできたコンパイラがstage2コンパイラだ。当然、stage2コンパイラも、テストコードをコンパイルし、生成物は正常に実行される(stage2test)。
stage2も、テストコードだけでなく、当然、自分自身のソースコードもコンパイルすることができる。その成果物を stage3 コンパイラと呼ぶ。このとき、stage1コンパイラ(ソース=自作、コンパイラ=gcc)、stage2コンパイラ(ソース=自作、コンパイラ=自作)、stage3コンパイラ(ソース=自作、コンパイラ=自作)となる。全てがうまく言っていれば、stage2 と stage3 はバイナリレベルで完全に一致するはずである。stage1とstage2はソースは同じだがコンパイラが異なるのでバイナリ一致しない。
昔のUNIXワークステーション上でシステムのコンパイラ(cc)を使ってgccをビルドするときに、自動でstage2==stage3のテストまで行われていた。今は最初からgccであるが。
C言語の完全な実装ではなく、セルフホストが目標の場合、ある程度の段階以降は、セルフホストするために必要な機能の実装のみにターゲットを絞ることができる。たとえば、浮動小数点演算などの実装はセルフホストには不要だ。また、自作コンパイラの機能が足りない場合、ソースコードをその機能の範囲しか使わないように修正することも可能だ。今回の場合、可変個引数関数の実装を諦めた。良くある迂回作として、switch-caseを使わずに if-elseだけで実装するとか、enumを使わずに#defineで済ますとか。
デバッグ手法
デバッガでできること、というのはCPUのアーキテクチャと密接に関係していて、CPUのアーキテクチャは『ヘネ・パタ』以後、そう変わらない。ひとつのデバッガに習得することは、他のデバッガにも将来の色々なデバッグにも応用可能だ。
コンパイラは複雑なピタゴラ装置みたいなものである。真に原因を探り当て、そこを正しく動作するようにすると、それまでまったくく動かなかったピタゴラ装置がいきなり稼働しだすというのは感動的な体験になるだろう。最初のドミノが倒れ、次のドミノが倒れるなら、その次も倒れる。つっかえているドミノを修正するのがデバッグ。残りバグ数が数えられずに、先が見えないなか、1つづつデバッグしていったら、いきなり最後までドミノが倒れ続け、全テストがパスする。
とくにコンパイラを作成する場合、元のソースが間違っていて誤動作すると言うケースと、コード生成が間違っていて生成物がちゃんと動かないというケースがある。最初はstege1の問題。その次がstage2の問題だ。
stage1コンパイラをビルドしstage1テストをパスさせるところまでは比較的容易に到達できる。しかし、stage2コンパイラがビルドできない(テストでカバーしきれいていないバグをコンパイラソースで踏んでいる)、stage2testがパスしない(コード生成のどこかにバグがある)という状態に陥り、これはコンパイラ作成に特有の課題でチャレンジングである。
さらに別の課題がある。stage1コンパイラはgccなどでビルドするのでデバッグ情報が入っている。stage1コンパイラが落ちる場合、stage1testが失敗する場合のトレースはソースコードレベルで可能なので、比較的容易だ。一方、stage2コンパイラは、デバッグ情報が埋め込まれていないの。stage2コンパイラをデバッグする場合は、ベタのマシン語をデバッグすることになる。もともと、自分で生成したコードなので、生成の方針などは理解しており、比較的読めてもいいはずだである。しかし、gdb によるシンボル無しのデバッグは、通常のIDEに慣れた体には雰囲気が異なる。
gdbの使い方については、別記事にまとめた。 https://nkon.github.io/Gdb-basic/
今回のコンパイラは中間コード方式であり、中間コードのダンプ機能が付いているので、それもデバッグの見通し付けに大変役にたった。
例1: コード生成のバグ(命令の仕様)
今回作成したコンパイラはCを読み込んでアセンブラを出力する。その出力にバグがあると、次のステージのコンパイラが正しく動かない。遭遇した例では、比較命令に関するもの。==や>=などのCの比較演算子はアセンブラでは主にcmp命令として実装される。テストケースには正の数の比較だけ書いてあったので、テストはパスしたのだが、コンパイラのソースコード中に負の数と比較する比較演算子を用いていた。実は、cmp命令のオペランドのビット幅によっては必要なまでに拡張され、その拡張が符号拡張ではなくたんにゼロ埋め拡張なのだ。
つまり、int i; i = -1; i == -1;としたとき、iは intなので32ビット、-1は即値なので64ビットとしていた。つまり、iは 0xffff_ffff。-1は0xffff_ffff_ffff_ffffとなる。cmp命令はiに相当するレジスタを64ビットに拡張して0x0000_0000_ffff_ffffつまり4294967295、一方-1は-1のまま。比較は失敗する。
このバグが forループの判定式に影響すると forループが終了せずに SEGV になる。その部分のソースコード的には正しく書けているので、真の原因に気づくまでデバッグは困難であった。しかも、正の数どうしの比較では正しく比較できるしテストもパスしているので、比較演算子に疑いの目が行きにくい。
ツリーを読んでいくと SEGV する→forループが正常に終了しない→アセンブラレベルで追いかけて行くと、cmp命令が正しくフラグをセットしない。→なぜか??となって、たぶん解決までに7時間ぐらいかかった(一日溶けた)。
例2: コード生成のバグ(ABIの実装)
他の例ではレジスタの使い方だ。現象としては、ある関数がSEGVする。しかも、ほとんどの場合は正常に動作するが、特定の関数から呼ばれた時のみSEGVする。原因を探ってみると、SEGVするときは、ポインタがセットされているべき引数にポインタがセットされていない。
原因は、呼び出し側の関数のコード生成にあった。x86-64 ABIでは rbp,rsp,r12,r13,r14,r15,rbxは呼ばれた側が保存しなければならない。しかし、関数プロローグで push rbxするのを忘れていた。その結果、(1)呼び出し側関数でローカル変数をたくさん使い rbxにもローカル変数を割り当てていた。(2)その後で関数を呼び出し、そのときに rbxが壊れていたままリータンして、(3)その後で、その壊れたrbxに割り当てられたローカル変数を使って、次の関数に引数として渡していた。
引数がオカシイからSEGVするところまではすぐに辿りつけた。しかし、なぜ引数が壊れるか、それが呼び出し経路に依存すること、さらにその原因が関数プロローグで呼び出し規約を守らないこと(他の関数では動いていたし、そんなに呼び出し規約に詳しくなかった)に原因があった。これも一日溶けた。
何も考えずに、スタックマシンとして構成していればシンプルでこういうバグは原理的に発生しなかったかもしれない。しかし、x86-64ABIは関数への引数渡しやローカル変数などで積極的にレジスタを使う(高速化のため)。レジスタ割当アルゴリズムを正しく実装しなければならないので難易度が高い。
例3: データ構造のバグ
コンパイラのコード中ではデータ構造(リンクやツリーなど)が頻繁に登場する。データ構造は作る側と使う側で別れており、作る側でミスがあってもそこは通過し、使う側でSEGVで落ちる。何回か遭遇すると対処も慣れてくる。賢いデバッガならデータ構造を視覚化してくれるが、今の状況ではそんなツールは使えない。デバッガでメモリダンプを繰り返して、紙にデータ構造とメモリアドレスを書き出す作業になる。
紙に書く
デバッガはプログラムの実行をコントロールしてくれるが、出力はメモリダンプとレジスタダンプだけだ。アセンブラ出力は表示してくれるが、ソースコードとの対応はやってくれない。そういった、現代的なデバッガがやってくれるGUIがない場合、それと同等のことを、紙に手書きで行う。Paper User Interface(PUI)というわけだ。面倒がらずに、データ構造や、ソースとアセンブラの対応、その時のレジスタの状態などを紙に書いていくと、画面を眺めていたときには見落としていたことにも気づきやすい。
コンパイラの技法
一般的なコンパイラ技法についてのメモ。
lexer
lexなどのツールもあるが、たいていの場合、手書きでも問題なく書けるだろう。1文字のシンボルはアスキーコードそのままのトークン種別、複数文字の予約後や識別子は、256以上の定数を割り当てることが一般的だろう。
parser
再帰降順パーサを手書きする場合と、yacc/bison などのツールを使う方法がある。今回は手書きの再帰降順パーサでなんとかなった。Cの文法は歴史的な理由があり、あまりきれいでないので、手書きで例外処理が多い感じのほうが馴染みやすいような印象もある。ツールですっきり書けるほど、もとの文法がきれいではない、ということ。また、セルフホストする場合は、少なくともパーサジェネレータが使う機能は100%サポートしなければならない。
そして、すでにコンパイラがある中であえてコンパイラを作るという挑戦をしているときに、依存ツールは少ないほうがそれらしい。
セルフホストの必要がないDSL(domain specific language)を作る場合などは、パーサジェネレータを使ったほうが快適に作れると思う。
semantic analyzer
お手本とした9ccではparserとsemantic analyzerを分けていて、parserはAST(抽象構文木)を作ることに専念している。意味付けやエラーチェックなどはsemantic analyzerで行う方針となっていた。たとえば、1 = 2+3; という文は、parserではそのままパスさせ、semantic analyzerでエラーにする。これは parserをシンプルに保つために有効な手法だった。しかし、Cの文法の複雑さゆえに、けっこうparserでも意味的なところに手を入れなければならない場面もある。
preprocessor
自作コンパイラの場合、プリプロセッサは gcc -E に任せてしまっても良い、という考えもある。今回は9ccに従ってプリプロセッサの一部実装を取り入れた。プリプロセッサの完全な実装は(コーナーケースの正確な仕様にアクセスしにくいこともあって)難しいと思う。しかし、使う部分の実装だけならなんとかなる。さらに、自分のコンパイラの場合には __MY_COMPILERを定義するようにしておくと、いろいろ役に立つ場面が出てくる。
ちょっと混乱したのが、ifというキーワードがプリプロセッサでもCの本文でも使われること。
実際には、プリプロセッサの実装というのは、プリプロセッサのインタプリタ(条件分岐やマクロ展開)を実装すること、とほぼ等しくなる。コンパイラを作っているはずが、いつの間にかインタプリタも作っている…。
IR generator
今回のコンパイラは9ccに習って中間言語方式を用いている。最初のコード生成の段階では、無限のレジスタを使える中間言語としてコード生成を行い、次の段階でx86-64の実レジスタを割り当て、さらにx86-64のコード生成の段階で、特有の事情を織り込む。マルチパス構成にすることで、各段階の仕事が簡素化される。このへんは、LLVMなどでの知見もたっぷり盛り込まれたものなのだろう。
最適化
今回のコンパイラでは、ほとんど最適化なるものをしていない。生成されたコードを見ると、mov r10,r10のような意味がないコードもたくさん並んでいる。将来的には、簡単な最適化を実行してみて、どれぐらい速度が変化するか確かめてみたいものだ。
例として、コード生成部に次のようなものを入れてみた。mov r10,r10のような無意味なコードを出力しない「最適化」だ。
case IR_MOV:
if (regs[r0] == regs[r2]) {
break;
}
emit2s("mov %s, %s", regs[r0], regs[r2]);
break;
ビルド時間やファイルサイズを比較してみる。
| 最適化無し | 最適化有り | |
|---|---|---|
| make stage1 | 731ms | 689ms |
| make stage2 | 313ms | 329ms |
| make stage3 | 330ms | 346ms |
| ls stage1cc | 157312 | 157320 |
| ls stage2cc | 1119088 | 1110890 |
実行ファイルのサイズはすこし小さくなったが、実行時間に有意差は無かった。レジスタコピーのコストは非常に低い、ということだろうか。
ちなみに、make stage2はstage1コンパイラが使われ、make stage3はstage2コンパイラが使われる。その実行時間の差は「gccが出力した実行ファイル」と「自作コンパイラが出力した実行ファイル」の実行速度を比較する指標となる。そう考えると、いい感じなのではなかろうか。ファイルサイズの比較結果は悲惨だ。make stage1で時間がかかっているのは、ディスクキャッシュの影響とgccが行っている最適化のための実行時間の影響が考えられる。
低レイヤ技術
ABI(Application Binary Interface)
今回のコンパイラはアセンブラを出力する。それ以外のオプションとしては、Cを出力したり、最近ではLLVMの中間言語(IR)を出力したり、直接バイナリを出力したり。
ソースコードをコンパイルした結果、アセンブラを出力する。そのアセンブラは、アセンブラでコンパイルされる。つまり、アセンブラが理解できる書式で書かなければならない。アセンブラとしては、一般的な gas を使う。コマンドラインでは gcc(コンパイラドライバ)から起動する。せっかくコンパイラを書いたのに gcc を結局使うのだ。
アセンブラはオブジェクトファイルを出力する。オブジェクトファイルをライブラリとリンクしたら実行ファイルができる。ライブラリはシステム提供のもの、リンカは gcc のリンカ(これも gcc から起動する)を使う。
つまり、コンパイラの出力は、アセンブラが理解できるだけでなく、ライブラリを使って、システムのライブラリとリンク可能にしなければならない。そうでなければ、同じ x86 のアセンブラを出力したとしても、リンクで失敗する。
前置きが長いが、こういった相互運用を可能にするのが、ABI(Application Binary Interface)である。いくつかのABIが存在するが、今回は x86_64 ABI を使う。Linux 上で 64bit プログラムで使われている一般的な形式だ。ABIを守っていれば逆に、どんな言語で書いたオブジェクトファイルでもリンクできる。
x86_64 ABIは旧来のものとは違いレジスタをなるべく活用しようとする設計になっている。必然的に、コンパイラが出力するアセンブリコードも旧来のスタックマシンを前提としたものからレジスタマシンを前提としたものに変えていかなければならない。このへんは、わりと新しい技術だと思う。
主にコンパイラ研究やLLVM方面の成果だと思うが、レジスタマシンであっても最初は無限個のレジスタが使えるレジスタマシン向けのアセンブリ(またはIR:中間言語)を生成し、そこから現実のレジスタにフットさせるという手法が使われる。その段階で、とりあえずスタックに積んでおくという実装よりも、現実のレジスタ数に合わせて、かつ規約を守るように詰め込む、というより複雑なアルゴリズムが必要になる。Cが最初に開発された時代にはスタックマシンが一般的だったため、それに依存した可変個数引数と<stdarg.h>で定められるva_*マクロなどの仕様が紛れ込んでいる。それをx86-64の呼び出し規約に合わせて再実装するのは、今回は時間の関係であきらめた。つまり、可変個数引数をサポートしない。
Basic Block, Static Single Assignment
コンパイラで最適化の祭に使われる技法。Basic Blockは内部に分岐を含まない1つの実行の塊。Static Single Assignmentは1度代入された変数は再代入されない形式。現代のコンパイラは、最適化の祭に単に最適化するだけでなく、まず、このような構造を作って、その上で最適化を行うようになっている。9ccはこのような実装を取り込んでおり、学習用としても優れている。
私自身の理解も怪しいので、詳しい内容はWikipediaの該当項目を見て欲しい。
結論
結論としては、このように色々楽しくて知見が得られるので、コンパイラを書こう。