RustでRTOSを作る(RP2040 Cortex-M0+)
Raspberry Pi Pico(RP2040)上で動作するRTOS(Real Time OS:リアルタイムOS)を自作する。技術コンセプトの実証のためのプロトタイプだが、タスク切換え、SysTickのハンドリング、タスクの停止、ペリフェラルにアクセスするデバイスドライバ、などの機能を持っている。類似の多くの情報があるが、Cortex-M3のマイコンをターゲットにしたものが多い。RP2040はCortex-M0+コアであり、更にマルチコアであり、それらの既存の情報がうまく適用できない場面が多い。本記事は、とくに差異において注意する点をとりあげた。また、組み込みRustの分野は進歩が早く、できるだけ新しいプラットフォーム(Embedded-Rustチームが提供するcortex-m, cortex-m-rt, HALなど)を活用するようにした。
主に『Rustで始める自作組み込みOS入門』の内容をなぞっているが、必要な箇所についてはCortex-M0+に対応している。アトミック操作、Mutexによる排他制御については『詳解 Rustアトミック操作とロック』が非常に参考になる。RP2040固有部分については『インターフェイス 2024年11月 ゼロから作るマルチコアOS』を参考にした。
RTOSを実装するということでは、タスク切換えがコアな技術となる。
それだけではなく、次のような技術が必然的に必要となり、それらはRTOS以外にも応用がきく技術だ。とくに、MutexとCellについては、この課題によって格段に自然に使いこなせるようにになった。
- プラットフォームであるARMの関数呼び出し規約、アセンブラ(ARM特有の命令、Cortex-M0とM3の違い)、インラインアセンブラの書き方
- マルチコアのハンドリング
- メモリマップの設計とリンカスクリプトやコンパイラ注釈を利用した割り当て方法
- ハードウエアリソースの初期化と複数タスクへの共有の方法。ハードウエア・レジスタは本質的に
static mutとなるが、Rustはデータ保護のために、そういうものを容認していない。Mutexによるロック、Cellによる内部可変、Optionによる定数初期化などの技術が必要 Mutexの実装、その裏にあるアトミック操作の実装と本質- ベアメタル環境でのグローバル・アロケータの実装と
allocクレートの使用。
今回の実装については、https://github.com/nkon/rrtosに履歴付きでアップしてある。この記事では省略した詳細についてはソースコードを直接参照してほしい。
目次
- 目次
- 主な構成と機能
- 前提とするハードウエア
cortex-m-rtによるエントリーポイント、初期化ルーチン、例外ハンドラ- Cortex-M0+(ARM-v6M,thumbv6m) で注意すること
- 関数呼び出し手順(AAPCS: Arm Architecture Procedure Call Standard)
- RP2040で注意すること
- タスク切換え
- タスクスケジューラ
- Mutexの実装
- グローバル・アロケータと
allocクレート - alloc::boxed::Box, Box::leak()
- SysTickハンドラ
- デバイスドライバ
- gdbの使い方
- 参考文献
主な構成と機能
- Raspberry Pi Pico上のRP2040上で動作するRTOS
- Cortex-M0+(ARM-v6M:thumbv6m)のデュアルコア
- 割り込み禁止によるクリティカルセクションではなく、RP2040のコアのSpinLockペリフェラルを使って排他制御を行う
- Cortex-M0+(ARM-v6M:thumbv6m)のデュアルコア
- SysTickを使った強制タスクスイッチ(非協調マルチタスク)で複数のタスクをを切り替えて並列実行する
- タスクの優先度は未実装
- リソースを消費し続けるアプリケーションタスクからも他のタスクに実行権が移る
- アイドルタスクが実行されている間はWFIでスリープする
- タスクのスリープを実装し、他のタスクを実行しているあいだ、そのタスクを休止することができる
- Embedded Rust プロジェクトで提供されるフレームワーク(
cortex_m,cortex_m_rt,Peripheral Access Crate(PAC)など)を利用する - Mutex, グローバルアロケータを実装し、
allocクレートが使える - ボード上のLEDを駆動するためのデバイスドライバを実装し、複数のアプリケーションタスクからデバイスを駆動できる
前提とするハードウエア
RP2040を搭載したRaspberry Pi Picoをハードウエアとする。安価だが、一般的に用いられているCortex-M3のシングルコアMCUとは違う点が多い。
プロジェクトの立ち上げ方法については別記事(Raspberry Pi PicoとRustで組み込みプログラム環境を整える)を参照。
cortex-m-rtによるエントリーポイント、初期化ルーチン、例外ハンドラ
cortex-m-rtは#[entry]、#[pre_init]、#[exeption]という関数修飾マクロを提供している。
#[entry]
必須。初期化ルーチン(慣習的にcrt0と呼ばれる)がメモリを初期化をしたあと、内部的に、fn mainが呼ばれ、fn mainは#[entry]が付けられた関数を呼ぶ(内部的には__cortex_m_rt_mainという関数になる)。
#[pre_init]
#[pre_init]が付けられた関数があれば、crt0が、fn mainを呼ぶ前にその関数を呼ぶ。
#[pre_init]関数と#[excption]関数(後述)は、unsafeモードで実行されるので、追加のunsafe指定は不要。
#[exception]
次の名前の関数に、#[exception]をつければ、それは例外ハンドラとなり、該当する例外が発生したときに呼ばれる。もしユーザがこれらの例外ハンドラを作成しなければDefaultHandlerが呼ばれる。
DefaultHandlerNonMaskableIntHardFaultMemoryManagement(a)BusFault(a)UsageFault(a)SecureFault(b)SVCallDebugMonitor(a)PendSVSysTick
(a) Not available on Cortex-M0 variants (thumbv6m-none-eabi)
(b) Only available on ARMv8-M
Rustの関数を書けば、割り込みベクタ(boot2の初期値である0x2000_0100から)への登録をおこなってくれるので便利。しかし、次の点でいえば、かえって不便とも言える。
- 自動で関数プロローグ、エピローグが挿入されてしまい、とくに例外ハンドラの場合は意図した動作に影響を与える。
- 登録先がFLASH中にあるデフォルトの割り込みベクタのため、あとからハンドラを差し替えたり、別のコアのためにSRAM上に割り込みベクタテーブルを構築したい場合に自由度がきかない。
VTORと割り込みベクタのアドレス
Cortex-Mは割り込みベクタテーブルのアドレスは固定ではなく可変。その先頭アドレスをPPBの中のVTORというレジスタ(0xe000_ed08)に設定する。
RP2040の通常の起動シーケンスにおいては、内蔵ROMの起動⇒boot2の実行。このときに、boot2がVTORを0x2000_0100(外付けFlashのboot2の次のエリア)にセットする。
cortex-m-rtの標準のリンカスクリプト(link.x)が.vector_tableというセクションを定めていて、そのセクションが0x2000_0100に割り付けられる。コード中では#[link_section=".vector_table.exception]"として、割り込みベクタテーブルを指定のセクションに配置する。また、上述のように#[exception]などをつければ、その関数を指定のベクタに登録できる。
起動後に割り込みハンドラを再割り当てしたい場合には、cortex-m-rtの機能の外になるが、unsafe extern "C" fn()の配列として、割り込みベクタテーブルをSRAM中に確保して、VTORをセットすればよい。
Cortex-M0+(ARM-v6M,thumbv6m) で注意すること
組み込みRustに関する記事や書籍も多い。しかし、それらのほとんどがCortex-M3またはそれ以上のプロセッサを前提としている。Cortex-M3はARM-v7Mアーキテクチャ(thumbv7em)である。しかし、今回ターゲットとしているRP2040はCortex-M0+で、アーキテクチャはARM-v6Mである。いくつかの命令や機能が実装されておらず、注意しなければならないことがおおい。
Raspberry Pi Pico2に搭載されているRP2350はCortex-M33デュアルコアであり、ほとんどの情報が適用できる。さらにRISC-Vコアも搭載されているので、そちらも試すことができる。素晴らしい。
アトミック命令
Rustでは言語レベルでデータ競合が防止されている。そこを「かいくぐる」手段としてMutexなどのロック手段が用いられる。
多くの場合、その実装にはAtomicU32などのアトミック変数が用いられる。そして、それらはコンパイルされるときに、MCUのアトミック演算命令を用いる。
しかし、Cortex-M0(ARM-v6M: thumbv6m)には、Cortex-M4(ARM-v7M: thumbv7em)にあるldrex, strex命令が存在しない。「ベアメタル用」でも多くのライブラリが、Atomic変数を用いたロックに依存しているので(例えばlazy-staticなど)、そういったクレートはCortex-M0+では使うことができない。
cortex-mでは、そこも考慮して、割り込み禁止を用いたロック(cortex=_m::interrupt::free)が提供されている。しかしRP2040ではそれも使えない(後述)。
即値命令
Cortex-M0+では多くの命令が16ビット固定長で32ビット拡張命令が少ない。それらの制限を受けるものの一つに、即値のビット長が小さい、ということがある。
たとえば16bitのcmp命令は即値部分が8bitなので、最大255までの即値とレジスタを比較することができる。一方、Cortex-M3は32bitのcmp.w命令があり、より大きな範囲の即値と比較することができる。
よって、Cortex-M0+で大きな即値比較する場合は、いったん、他のレジスタにロードしてから比較する。その場合でも、ロードされる即値はPC相対でロードする命令にアセンブラによって書き換えられる。
Cortex-M3の場合
asm!(
"cmp lr, =0xfffffff9",
);
Cortex-M0の場合
asm!(
"ldr r3, =0xfffffff9",
"cmp lr, r3",
);
Cortex-M0のアセンブラ
10000c14: 4b0a ldr r3, [pc, #0x28] @ 0x10000c40 <PendSV+0x3c>
10000c16: 459e cmp lr, r3
...
10000c40: f9 ff ff ff .word 0xfffffff9
スタックに積めるレジスタ
もうひとつのCortex-M0+の命令の制限として、push,pop命令で扱えるレジスタセットが限られている、という点がある。
x86とはことなり、armの場合は、複数のレジスタをまとめてpush/popできる。pushするレジスタはビットマップ形式で表現されており、ビットが立っているレジスタがプッシュされる。
16bitのpush命令ではレジスタリストに割り当てられたビットは8bitなので、r0-r7とlrしかpushできない。r8-r12をプッシュしたいときは、いったんr0-r7にコピーしてからプッシュする必要があり、非常に使い勝手が悪くなる。
しかし、Cortex-M3は32ビットのpush.w命令がサポートされているので、push命令ですべてのレジスタをpushできる。
ldmia,stmiaが元レジスタを壊す
複数のレジスタをロード、ストアするldmia,stmia命令だが、Cortex-M0には、退避先を示すレジスタが命令実行後に壊れるldmia!,stmia!命令しかサポートされていない。もし壊されてはならないときは自力でスタックに対比して置かなければならない。
関数呼び出し手順(AAPCS: Arm Architecture Procedure Call Standard)
ARMプロセッサ上での関数呼び出し規約は必修だ。以下はAAPCS32に定められる32ビットプロセッサの呼び出し規約の概要。詳細は仕様書を参照のこと。
コアレジスタ
| 名前 | 役割 | 例外 | push |
|---|---|---|---|
| r0 | 引数1、結果1、スクラッチ | 保存 | サポート |
| r1 | 引数2、結果2、スクラッチ | 保存 | サポート |
| r2 | 引数3、 スクラッチ | 保存 | サポート |
| r3 | 引数4、 スクラッチ | 保存 | サポート |
| r4 | 汎用 | サポート | |
| r5 | 汎用 | サポート | |
| r6 | 汎用 | サポート | |
| r7 | 汎用 | サポート | |
| r8 | 汎用 | ||
| r9 | 汎用 | ||
| r10 | 汎用 | ||
| r11 | 汎用、フレームポインタ | ||
| r12 | IP | 保存 | |
| r13(sp) | スタックポインタ | ||
| r14(lr) | リンクレジスタ | 保存 | サポート |
| r15(pc) | プログラムカウンタ | 保存 |
r0-r3は引数を渡す。入り切らない場合はスタックに積まれる。- つまり、速度のためには、引数の数は4個までが望ましい。
&selfがある場合はr0となるので残りは3つ。
- つまり、速度のためには、引数の数は4個までが望ましい。
- 戻り値は通常
r0だが、r1を使って8バイトまでの構造体を返せる。 r4-r8,r10,r11はローカル変数のために使われる。はみ出す場合はスタック。Cortex-M0+(Thumb命令セット)の場合はr4-r7がすべての命令でサポートされている。- 呼び出された関数は
r4-r8,r10,r11,spを壊してはならない。 - 関数からリターンするときは
blx(通常の関数)、bx(末尾関数)を使う。blx,bxの場合は状態変更なども行うpop pcも使用可能mov pc, Rmは非推奨
RP2040で注意すること
SIO::SpinLock
一般的なCortex-M0+コアと異なり、RP2040はCortex-M0+のデュアルコアである。
最も大きな違いは、割り込み禁止によるクリティカル・セクションが作れないこと。割り込み禁止はコアごとに動作する。一つのコアで割り込みを禁止しても、他方のコアは自由にクリティカルなメモリにアクセスできてしまう。
それに対する支援として、ハードウエアでSpinLockが提供されている。これは1ビットの値を持つレジスタで、SIO領域に32個存在し、双方のコアからアクセスできる。
それを使って両方のコアで有効なスピンロックを実装できる。
cortex-mフレームワークではrp2040_halクレートがsio::spinlock0-31を提供している。
boot2
もうひとつ特徴的なものはboot2ブートローダだ。一般的なシステムでは、リセットアドレスからFLASHの先頭にジャンプし、ユーザコードをFLASHの先頭におけば、即座に実行される。
RP2040では、内蔵ROMは、外付けフラッシュの先頭にジャンプするが、そこにはboot2と呼ばれるブートローダを書き込む。そして、boot2がユーザコードを実行する。通常はboot2はBSP(Board Support Package)クレートがハンドリングするが、自前で置き換えることもできる(boot-kプロジェクトを参照)。
上述のように、Cortex-MはVTORによる設定で割り込みベクタをメモリ上の任意の場所に配置できる。しかしboot2はFlash上の0x2000_0100に割り込みベクタを配置することに注意が必要。
タスク切換え
RTOSと自称するための最も基本的な機能であるタスク切換えについて。
最も簡単にいえば、タスク切換え=タスクごとにレジスタとスタックとPC(命令ポインタ: IntelではIP(インストラクションポインタ)と呼ばれるが、ArmではPC(プログラムカウンタ)と呼ばれる)を切り替えること。そうすれば、タスクが切り替わったときに、そのタスクは自分の「世界(PC、レジスタ、スタック)」が見える。メモリ空間はタスクごとに分離されていない。
Cortex-M上で動作する場合、コアが提供するタスク切換えの支援機構を使う。
特権モード
- Mode: Handler, Thread。例外ハンドリングはハンドラモードで、それ以外はThreadモードで実行される。リセット直後はスレッドモード。
- Privilege: Privileged, Unprivileged。特権モードでは全ての命令が実行可能。非特権モードでは命令が制限される。CONTROL.nPRIVビットが1のときは非特権モード。Unprivileged拡張の実装はMPUによって任意。RP2040は実装あり。
- Stack pointer: Cortex-MはMain(MSP), Process(PSP)の2つのスタックポインタを持つ。ハンドラモードでは常にMSPが使われる。CONTROL.SPSELが1のときはPSPが使われる。選択されているスタックポインタがSP(r13)にエイリアスされる。
この3つを組み合わて、次の構成とする。
| Mode | Privilege | Stack Pointer | Usage |
|---|---|---|---|
| Handler | Privileged | Main | 例外ハンドラ |
| Thread | Privileged | Main | OSの実行 |
| Thread | Unprivileged | Process | アプリの実行 |
ARMがだしている図がわかりやすい。
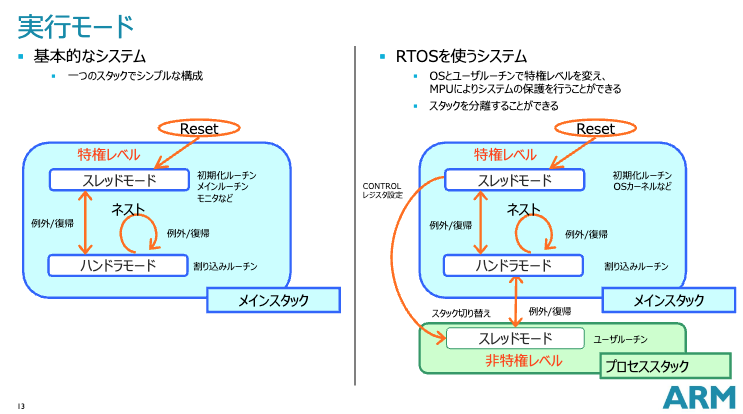
https://os.mbed.com/media/uploads/MACRUM/cortex-m_mbed_deep-dive_20140704a.pdf
例外フレーム
例外が発生したとき、Cortex-Mはいくつかの情報を「呼び出し側の」スタックに積んで、例外ハンドラに飛ぶ。それらは「例外フレーム」と呼ばれる。例外フレームは8バイトアラインとなっている。もしその時のSPが4バイト境界にいたときは、アライメントが調整されて、例外フレームが積まれる。
例外から戻ってきたときは、例外フレームは元のレジスタに復帰される。それ以外のレジスタは自前で戻す必要がある。
pub struct ExceptionFrame {
r0: u32,
r1: u32,
r2: u32,
r3: u32,
r12: u32,
lr: u32,
pc: u32,
xpsr: u32,
}
lr(リンクレジスタ)は、通常関数呼び出し時には、戻りアドレスがセットされるが、例外ハンドラに飛んだ場合は、次の特別なアドレス(EXC_RETURN)になっている。
- 0xFFFF_FFF1: ハンドラモードから呼ばれた。
- 0xFFFF_FFF9: 特権モード、かつ、スレッドモードから呼ばれた。
- 0xFFFF_FFFD: 非特権モード、かつ、スレッドモードから呼ばれた。
逆に、このアドレスにリターン(bxまたはPCにpop)すると、次の動作をする。
- 0xFFFF_FFF1: ハンドラモードに戻る。レジスタ類はMSPから復帰され、その後の実行もMSPが使われる。
- 0xFFFF_FFF9: スレッドモードに戻る。レジスタ類はMSPから復帰され、その後の実行もMSPが使われる。(カーネル実行)
- 0xFFFF_FFFD: スレッドモードに戻る。レジスタ類はPSPから復帰され、その後の実行もPSPが使われる。(アプリ実行)
そして、実行を再開する。
- 戻り先の
SP(MSPまたはPSP)が指している例外フレームを復帰MSP,PSPの値は例外ハンドラの呼び出しで変化しない
- そこに含まれていた
PCから実行を再開
タスク切換えの実装(SVCall Handler)
Cortex-Mではsvc命令を実行することによってSVCall例外を発生させる。
SVCallハンドラはカーネルモードとアプリケーションモードの実行を切り替えるように実装する。
つまり、アプリケーションから呼ばれたらカーネルに、カーネルから呼ばれたらアプリケーションに移行する。
- アプリケーション: スレッドモード、非特権モード、PSP
- カーネル: スレッドモード、特権モード、MSP
これらを踏まえ、SVCallの例外ハンドラは次の擬似コードのように書ける。
if lr == 0xFFFF_FFF9 { // もし特権モードから呼ばれたら
CONTROL.nPRIV = 1; // 非特権フラグをセットして
bx 0xFFFF_FFFD; // 非特権、スレッドモードで実行再開。PSPレジスタを使う。
// PSPで指定されていた例外フレームを復帰し、その`PC`から実行を再開
} else { // もし非特権モードから呼ばれたら
CONTROL.nPRIV = 0; // 非特権フラグをクリアして
bx 0xFFFF_FFF9; // 特権、スレッドモードで実行再開。MSPレジスタを使う。
// PSPで指定されていた例外フレームを復帰し、その`PC`から実行を再開
}
実際にRustで(というかインラインアセンブラで)書くと次のようになる。
#[exception]
fn SVCall() {
unsafe {
asm!(
"pop {{r7}}", // Adjust SP from function prelude "push {r7, lr};add r7, sp, #0x0"
"pop {{r3}}", // dummy pop for lr
"ldr r3, =0xfffffff9", //If lr(link register) == 0xfffffff9 -> called from kernel
"cmp lr, r3",
"bne 1f",
"movs r0, #0x3",
"msr CONTROL, r0", //CONTROL.nPRIV <= 1; set unprivileged
"isb", // Instruction Synchronization Barrier
"ldr r3, =0xfffffffd", // Return to Thread+PSP
"mov lr, r3",
"bx lr",
"1:",
"movs r0, #0",
"msr CONTROL, r0", //CONTROL.nPRIV <= 0; set privileged
"isb",
"ldr r3, =0xfffffff9", // Return to Thread+MSP
"mov lr, r3",
"bx lr",
options(noreturn),
);
};
}
実際のアセンブラが次。
10001130 <SVCall>:
10001130: b580 push {r7, lr}
10001132: af00 add r7, sp, #0x0
10001134: bc80 pop {r7}
10001136: bc08 pop {r3}
10001138: 4b09 ldr r3, [pc, #0x24] @ 0x10001160 <SVCall+0x30>
1000113a: 459e cmp lr, r3
1000113c: d107 bne 0x1000114e <SVCall+0x1e> @ imm = #0xe
1000113e: 2003 movs r0, #0x3
10001140: f380 8814 msr control, r0
10001144: f3bf 8f6f isb sy
10001148: 4b06 ldr r3, [pc, #0x18] @ 0x10001164 <SVCall+0x34>
1000114a: 469e mov lr, r3
1000114c: 4770 bx lr
1000114e: 2000 movs r0, #0x0
10001150: f380 8814 msr control, r0
10001154: f3bf 8f6f isb sy
10001158: 4b01 ldr r3, [pc, #0x4] @ 0x10001160 <SVCall+0x30>
1000115a: 469e mov lr, r3
1000115c: 4770 bx lr
1000115e: defe trap
10001160: f9 ff ff ff .word 0xfffffff9
10001164: fd ff ff ff .word 0xfffffffd
これを踏まえて逐行解説する。
#[exception]
fn SVCall() {
- この関数を
SVCallの例外ハンドラとして登録する。cortex-m-rtによって、関数のアドレスがベクタテーブル(フラッシュの先頭付近:0x2000_01c0)に登録される。unsafe { asm!(
- インラインアセンブラなので
unsafe。"pop {{r7}}", // Adjust SP from function prelude "push {r7, lr};add r7, sp, #0x0" "pop {{r3}}", // dummy pop for lr - アセンブラコードを見ればわかるように、関数プレリュードが関数の先頭に自動で挿入されるので、補正する。最初の
pop {r7}は、push r7を戻す。 - 次の
pop {r3}は、pushされたlrをpopしてSPの位置をあわせる。 - インラインアセンブラ中では
{,}は{{,}}と書く10001130: b580 push {r7, lr} 10001132: af00 add r7, sp, #0x0"ldr r3, =0xfffffff9", //If lr(link register) == 0xfffffff9 -> called from kernel "cmp lr, r3", lrと0xffff_fff9の比較。即値で比較できないので、いったんr3にロードする。- 例外ハンドラに飛んでくる前に
r0-r3,r12は例外フレームに積まれるので、例外ハンドラ中ではr3は破壊可能。"bne 1f", lrが0xffff_fff9と等しくなければ(=非特権モードから呼ばれたら)、後方の:1ラベルにジャンプ。"movs r0, #0x3", "msr CONTROL, r0", //CONTROL.nPRIV <= 1; set unprivileged "isb", // Instruction Synchronization Barrierlrが0xffff_fff9と等しければ(=特権モードから呼ばれたら)、つづいてここが実行される。CONTROLレジスタに0x03(=nPRIVフラグ)をセットしたいが、いったんr0にロードする。CONTROLレジスタにロードするときは特別命令であるmsrを使う。CONTROLレジスタを変更したあとは、メモリバリア命令isbで変更が有効になるまで待つ。"ldr r3, =0xfffffffd", // Return to Thread+PSP "mov lr, r3", "bx lr",- リターンアドレスを
0xffff_fffd(=非特権、スレッド、PSP)にセット(EXC_RETURN)。Cortex-M0+ではlrに直接この長さの即値をロードできないので、いったんr3にロード。- アセンブラでは
r3への即値ロードとして書かれているが、実際にはPC相対ロードにアセンブルされる。
- アセンブラでは
lrにリターンアドレスをセット。lrにジャンプ。"1:", "movs r0, #0", "msr CONTROL, r0", //CONTROL.nPRIV <= 0; set privileged "isb", "ldr r3, =0xfffffff9", // Return to Thread+MSP "mov lr, r3", "bx lr",lrが0xffff_fff9と等しくなければ(=非特権モードから呼ばれたら)、ここに飛んでくる。- あとは上と同様。
0xffff_fff9(=特権、スレッド、MSP)にEXC_RETURNする。options(noreturn), ); }; }- この関数からはリターンしない。
1000115e: defe trap 10001160: f9 ff ff ff .word 0xfffffff9 10001164: fd ff ff ff .word 0xfffffffd - 関数末尾にオーバーラン防止用の
trapとPC相対で参照される即値が配置される。
メモリマップ
本OSでのメモリマップは次のとおり。
- 外付けフラッシュ(0x1000_0000-0x1020_0000)
- 先頭に
boot2ブートローダ。サイズは0x100 - ユーザ領域の先頭は割り込みベクタ。サイズは0xc0
- そのあとが通常のコード
- 先頭に
- 内蔵SRAM(0x2000_0000-0x2004_0000)
- 先頭部にヒープ
- 末尾付近にカーネルスタック
- カーネルスタックの後ろに
.uninitセクションがあり、アプリスタックを割り当てるアプリスタックは1024バイト(0x400)とした - 最後尾は
defmtが使う
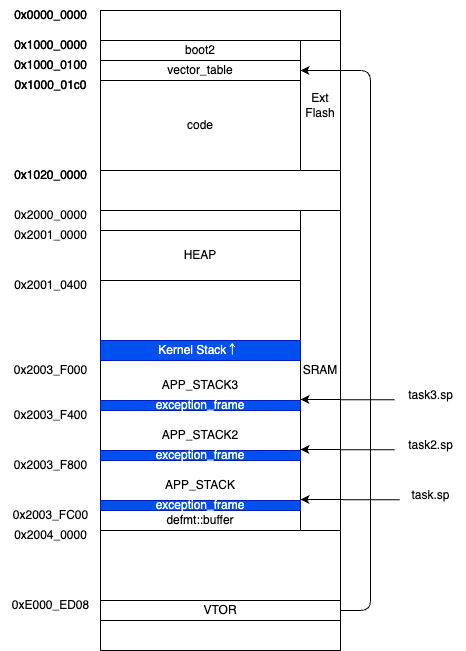
アプリスタック領域の初期化
非常に大雑把にいえば、タスクの作成=タスクスタック領域の作成+スタックの初期化+タスク構造体の作成+タスク関数ポインタの登録。
※すみません、タスクとアプリの用語が混在していますが、同じものを指しています。
SVCallハンドラで実行モードの切り替えができるので、ここでは実行される環境(タスク情報を保存するタスク構造体、タスクごとのスタック領域)を用意し、それらが適切に切り替わるように実装する。
- タスクスタック領域は、今回の実装では静的領域に確保する
- タスクスタック領域は
.uninitセグメントの中にリンカで割り当てる .uninitセグメントの上に、カーネルスタックが割り当てられる
- タスクスタック領域は
- タスクSPはタスクスタック領域の中を指す
- スタック操作によってタスクSPはタスクスタック領域の中を移動する
- pushされるとアドレスが減る、popされるとアドレスが増える
- スタック操作によってタスクSPはタスクスタック領域の中を移動する
- タスクスタック領域の「底」に初期例外フレームを作成し、適切に初期化する
- タスクSPの初期値は初期例外フレームの「上」を指す。
- タスク実行中に例外が発生したときは、その時の
SPの上に例外フレームが積まれる
- タスク構造体はヒープ中に作成する。ベアメタルでヒープを使うために、
GlobalAllocatorを定義し、allocクレートを使用する。GlobalAllocatorはHEAP領域からメモリを割り当てる- 今回の実装では、要求されたメモリを割り当ててポインタを進めるが、開放しない「Bump Pointer Allocator」を実装する
- タスク構造体はリンクリストでつなげて管理し(リンクリストのノードもヒープ中に確保される)、カーネルのスケジューラによって順次実行される。
pub const STACK_SIZE: usize = 1024;
#[repr(align(8))]
pub struct AlignedStack(pub MaybeUninit<[u8; STACK_SIZE]>);
- ひとつのアプリごとに1024バイトのスタック領域を割り当てる
- スタック領域の初期化
- 8バイトアライン
- u8 x STACK_SIZEの配列
- 初期化されていない(
MaybeUninit) - 一つしか要素がないが、構造体名を
AlignedStack#[link_section = ".uninit.STACKS"] static mut APP_STACK: AlignedStack = AlignedStack(MaybeUninit::uninit()); let task = Box::new(Task::new( unsafe { &mut *addr_of_mut!(APP_STACK) }, app_main, )); let item: &'static mut ListItem<Task> = Box::leak(Box::new(ListItem::new(*task))); SCHEDULER.write().push_back(item);
.uninitセクションに割り当てるstatic mutとして変数を確保する。コレに対する操作はunsafeとなる- タスク構造体(
Task)をヒープ上に割り当てる - リストノードを作成する
- この関数のスコープを抜けてもヒープ上に割り当てたタスク構造体のメモリ領域が有効であるように
Box::leak()で&'staticな変数に束縛させる
- この関数のスコープを抜けてもヒープ上に割り当てたタスク構造体のメモリ領域が有効であるように
- スケジューラに登録する(後述)
- スケジューラがなくても、カーネル⇔単一のアプリケーションタスク、のタスク切換えは可能
タスク構造体
タスクを切り替えるときに保存しなければならない情報を保持するために、タスク構造体を作り、タスクごとのSP、レジスタを保存する。
- 例外フレームに保存されないレジスタ(
r4-r11)を保存/復帰する。 - タスクごとの
SPを保存/復帰する。
pub struct Task<'a> {
sp: usize,
regs: [u32; 8], // r4, r5, r6, r7, r8, r9, r10, r11
state: TaskState,
wait_until: Option<u32>,
marker: PhantomData<&'a u8>,
}
spに、このタスクのSPを保存- 前述のように、タスクごとのスタック領域を作成し、タスク構造体の
spがその中を指すようにしておく
- 前述のように、タスクごとのスタック領域を作成し、タスク構造体の
regsにr4-r11を保存する。しかし、Cortex-M0+(ARM-v6M)のpush命令の制限のため、今回はr4-r7しか保存しない- 本来であれば
r8-r11もr4-r7経由で保存するべき r0-r3は例外フレームに積まれるのでここで保存しなくても良い
- 本来であれば
state,wait_untilは後で使用markerは、ライフタイムを管理するためのサイズが無いメンバー
impl<'a> Task<'a> {
pub fn new(stack: &'a mut AlignedStack, app_fn: fn() -> !) -> Self {
let sp = (stack.0.as_ptr() as usize) + STACK_SIZE - size_of::<ExceptionFrame>();
let exception_frame: &mut ExceptionFrame = unsafe { &mut *(sp as *mut ExceptionFrame) };
unsafe {
exception_frame.set_r0(0);
exception_frame.set_r1(0);
exception_frame.set_r2(0);
exception_frame.set_r3(0);
exception_frame.set_r12(0);
exception_frame.set_lr(0);
exception_frame.set_pc(app_fn as usize as u32);
exception_frame.set_xpsr(0x0100_0000); // Set EPSR.T bit
}
Task {
sp,
regs: [0; 8],
state: TaskState::Ready,
wait_until: None,
marker: PhantomData,
}
}
}
- タスク構造体(これはヒープ上に割り当てられる)の初期化時に、タスクスタック領域に初期例外フレームを作成する。
- 初期PCはタスク関数のアドレス
- EPSRのTビットをセットしてThumbモードでの実行を指定
- タスクの初期
SPは初期例外フレームの先頭を指すspに保存されたスタックポインタの値はタスクスイッチ時にPSPにセットされる
タスク切換えの実装(fn execute_task)
タスクを切り替えるときは、svc命令を実行すれば、上述のSVCallハンドラが実行され、タスクが切り替わる。
カーネルから次の関数を呼べば、事前準備を行い、タスクの実行に切り替わり、その実行が終わって戻ってきたときの処理を行う。
GitHub Pagesで使っているJekyllの制限により、二重波括弧がエスケープされているが、実際にはエスケープは不要。
#[inline(never)]
fn execute_task(mut sp: u32, regs: u32) -> u32 {
unsafe {
asm!(
"push {{r4, r5, r6}}", // r7, lr are pushed by prorogue
"push {{ {regs} }}", // save r1
"ldmia {regs}!, {{r4-r7}}", // load r4-r7 from backup
"msr psp, {sp}",
"svc 0",
"pop \{\{ {regs} \}\}",
"stmia {regs}!, {{r4-r7}}", // save r4-r7 to backup
"mrs {sp}, psp",
"pop {{r4, r5, r6}}", // r7, pc are popped by prorogue
sp = inout(reg) sp, regs = in(reg) regs,
);
};
sp
}
タスクごとのメンバ関数として、次のラッパーを作る。
pub fn exec(&mut self) {
info!("execute task {:x}", self.sp);
self.sp = execute_task(self.sp as u32, &mut self.regs as *mut u32 as u32) as usize;
}
アセンブラを参照しながら、逐行解説。
10001104 <rrtos::task::execute_task::h43d78dfdd0bc44d5>:
10001104: b580 push {r7, lr}
10001106: af00 add r7, sp, #0x0
10001108: b470 push {r4, r5, r6}
1000110a: b402 push {r1}
1000110c: c9f0 ldm r1!, {r4, r5, r6, r7}
1000110e: f380 8809 msr psp, r0
10001112: df00 svc #0x0
10001114: bc02 pop {r1}
10001116: c1f0 stm r1!, {r4, r5, r6, r7}
10001118: f3ef 8009 mrs r0, psp
1000111c: bc70 pop {r4, r5, r6}
1000111e: bd80 pop {r7, pc}
#[inline(never)]
fn execute_task(mut sp: u32, regs: u32) -> u32 {
- 関数呼び出し規約どおりに、第一引数(
sp)がr0、第二引数(regs)がr1に割りあたって欲しいので#[inline(never)]とする - 第一引数は、タスクごとの
SP、第二引数はレジスタ退避用のバッファunsafe { asm!( "push {{r4, r5, r6}}", // r7, lr are pushed by prorogue - 例外フレームに保存されない
r4-r6を現在のスタック(=この関数を呼ぶのはカーネルなので、カーネルのスタック)に保存する r7,lrは関数プレリュードでスタックにpushされている"push \{\{ {regs} \}\}", // save r1- Cortex-M0+(ARM-v6M)の場合、その後の
ldmia!命令でr1が壊されるので、スタックに保存するasm!末尾のパラメータ指定により、{regs}はr1に展開される"ldmia {regs}!, {{r4-r7}}", // load r4-r7 from backup
- タスクの保存バッファからタスクのレジスタ(`r4-r7’)をロードする
r0-r3,r12は例外フレームから復帰されるr8-r11は、現在の実装では無視する"msr psp, {sp}",
- タスクの
SPをPSPにロードする。{sp}はr0に展開される"svc 0",
svc命令を実行し、SVCall例外を発生させるSVCallハンドラが呼ばれ、EXC_RETURN=0xffff_fffdにリターンする- 非特権、スレッド、PSPで、引数
spで示されたスタック、例外フレームから復帰したレジスタ、レジスタバッファregsでで復帰したレジスタ(PCも含む)、の状態で、指定したタスクが実行される
- 非特権、スレッド、PSPで、引数
- タスク側で
svc命令が呼ばれたら、再度SVCallハンドラが呼ばれ、EXC_RETURN=0xffff_fff9によって、ここに実行が戻って来る。"pop \{\{ {regs} \}\}", - タスクのレジスタ退避バッファのアドレスが入っていた
r1をスタックから復元する"stmia {regs}!, {{r4-r7}}", // save r4-r7 to backup - タスク側で使っていた
r4-r7をレジスタ退避バッファに保存する"mrs {sp}, psp", - タスクの
PSPをタスク構造体に保存するためにr0にセット- 関数呼び出し規約により
r0はこの関数(execute_task)の戻り値となる"pop {{r4, r5, r6}}", // r7, pc are popped by prorogue
- 関数呼び出し規約により
r4-r6をカーネルスタックから復帰する- 現在の実装では
r8-r11は無視
- 現在の実装では
- この後に、下の関数プロローグが挿入される
r7をスタックから復帰するpcをスタックから復帰=呼び出し時のlr(=呼び出し元のアドレス)から実行継続=関数リターン
1000111e: bd80 pop {r7, pc}
sp = inout(reg) sp, regs = in(reg) regs,
- 第一引数(
sp)は入出力、第二引数(regs)は入力専用であることをコンパイラに伝える); }; sp } - タスクの
PSPをfn execute_task()の戻り値として返す- このタスク実行の間にSPが変化しているので、次の実行再開に備えて
PSPをタスク構造体に上書き保存する。
- このタスク実行の間にSPが変化しているので、次の実行再開に備えて
タスクスケジューラ
タスクを次々に実行する
タスク構造体を作成し、リストにつなげ、それぞれのタスクごとに上記のTask::exec()を呼び出せば、次々にタスクが実行される。それぞれのタスクは無限ループとして実装される。
タスクの無限ループのなかで、svc命令を呼び出せば、カーネル側(カーネル側ではタスクスケジュールが実行されている)に制御が戻り、タスクスケジューラによって次のタスクの実行が再開される。
asm!("svc 0")をラップするようなback_to_kernel()というライブラリ関数を提供し、アプリ側はそれを呼ぶことによって、協調的マルチタスクが実現される。
pub fn back_to_kernel() {
unsafe {
asm!("svc 0");
}
}
fn app_main() -> ! {
let mut i = 0;
loop {
info!("app_main(): {}", i);
i += 1;
syscall::back_to_kernel();
}
}
アイドルタスクでスリープする
組み込みソフトウエアにとっては低消費電力化は必須だ。通常のRTOSを使ったシステムでは、最低優先度のタスクとしてアイドルタスクを作成し、その中でcortex_m::asm::wfi()を呼び出してスリープする。
一方で、SysTickタイマが定期的に例外を発生させるので、MCUはウェイクアップし、タスクの実行が再開される。
今回はタスク優先度を未実装なので、タスクチェーンの中にアイドルタスクをつなげておくことによって、他のタスクの実行が完了したらSysTick割り込みがかかるまではスリープするようにする。
また、あるタスクが無限ループで他のタスクに実行を譲渡しない場合場合でも、SysTickタイマによって、カーネルに制御が戻るようにしておけば、そのタイミングで他のタスクに強制的に実行がうつる。非協調的マルチタスクが実現される。リアルタイムOSを自称するのであれば、あるタスクがCPU時間を消費しようとしていても、必要な他のタスクに実行を移さなければリアルタイム性は実現できない。
// 無限ループタスク。SysTick割り込みによってタスクスケジューラに制御が戻され、次のタスクが実行される
fn app_main2() -> ! {
let mut i = 0;
loop {
info!("app_main2(): {}", i);
i += 1;
for _j in 0..1000000 {
asm::nop();
}
}
}
// アイドルタスク。このタスクが実行されるとMCUはスリープする。SysTick割り込みや他の割り込みで目覚める
fn app_idle() -> ! {
loop {
info!("app_idle() wfi");
cortex_m::asm::wfi();
}
}
// SysTickハンドラ。カウンタを増加させ、カーネル(タスクスケジューラ)に制御を戻す
#[exception]
fn SysTick() {
systick::count_incr();
asm!("svc 0");
}
タスクの休止状態とスリープ
タスクの状態として、Ready(タスクスケジューラによって実行が与えられたら実行可能な状態)とBlocked(実行が与えられても実行ができない状態)を定義し、これらをタスク構造体のメンバとしてもたせる。
実行できない状態とは、(未実装だが)データを受信待ちしている状態であったり、タスクがスリープしている状態だ。
これを使えば、Delay機能が実現される。このタスクは指定した時間だけ実行が停止するが、その間も他のタスクは実行を継続する。
システムでは、SysTickが(通常1msごとに)にカウンタを増やしている。wait_until()関数で現在のカウント値より5先の値を指定すれば、それまでタスクはBlocked状態になり実行されない。これによってマルチタスクでLEDが点滅する。
スケジューラはSysTickの値が指定する値になるまで、そのタスクを実行しない。
pub fn wait_until(&mut self, tick: u32) {
self.wait_until = Some(tick);
self.state = TaskState::Blocked;
syscall::back_to_kernel();
}
fn app_main3() -> ! {
let mut i = 0;
loop {
info!("app_main3(): {}", i);
i += 1;
led::toggle();
SCHEDULER
.write()
.current_task()
.unwrap()
.wait_until(systick::count_get().wrapping_add(5));
}
}
タスクの生成とスケジューラへの登録
かなりベタだが、次のコードでタスクを生成してタスクスケジューラに登録している。
.uninitセクションにアプリケーションスタックを割り当て- タスクをヒープ上に生成し
- リンクノードをヒープ上に生成し
- タスク・スケジューラのリンクリストに登録する
最期にタスクスケジューラの実行を開始。
#[link_section = ".uninit.STACKS"]
static mut APP_STACK: AlignedStack = AlignedStack(MaybeUninit::uninit());
let task = Box::new(Task::new(
unsafe { &mut *addr_of_mut!(APP_STACK) },
app_main,
));
let item: &'static mut ListItem<Task> = Box::leak(Box::new(ListItem::new(*task)));
SCHEDULER.write().push_back(item);
info!("task is added");
#[link_section = ".uninit.STACKS"]
static mut APP_STACK2: AlignedStack = AlignedStack(MaybeUninit::uninit());
let task2 = Box::new(Task::new(
unsafe { &mut *addr_of_mut!(APP_STACK2) },
app_main2,
));
let item2: &'static mut ListItem<Task> = Box::leak(Box::new(ListItem::new(*task2)));
SCHEDULER.write().push_back(item2);
info!("task2 is added");
#[link_section = ".uninit.STACKS"]
static mut APP_STACK3: AlignedStack = AlignedStack(MaybeUninit::uninit());
let task3 = Box::new(Task::new(
unsafe { &mut *addr_of_mut!(APP_STACK3) },
app_main3,
));
let item3: &'static mut ListItem<Task> = Box::leak(Box::new(ListItem::new(*task3)));
SCHEDULER.write().push_back(item3);
info!("task3 is added");
#[link_section = ".uninit.STACKS"]
static mut APP_IDLE: AlignedStack = AlignedStack(MaybeUninit::uninit());
let idle_task = Box::new(Task::new(unsafe { &mut *addr_of_mut!(APP_IDLE) }, app_idle));
let item_idle: &'static mut ListItem<Task> = Box::leak(Box::new(ListItem::new(*idle_task)));
SCHEDULER.write().push_back(item_idle);
info!("idle_task is added");
SCHEDULER.read().exec();
Mutexの実装
RTOSの実装には、どうしてもタスク間、タスク-カーネル間で共有されるデータが存在する。Rustでは言語レベルで変数の共有が禁止されており、それを「かいくぐる」ためにMutexが使われる。Mutexの実装はunsafeだが、Mutexを使うときにはunsafeは不要。
RustでのMutex
通常のCなどのライブラリでは、Mutex変数があり、それをロックしている間に排他的な操作を行う。複数の箇所で排他的な操作を行う場合は、同じ「Mutex変数」を使ってロックをとる。
Rustの場合は、Mutexはジェネリック型となり「保護される変数を格納」するようになる。中身のデータを使うときに、Mutexによる保護が強制される。
std環境ではOSの機能を用いて実装されたstd::sync::Mutexが提供される。core環境ではMutexライブラリは提供されないので自分で実装する必要がある。cortex_m::interrupt::mutexは、割り込み禁止を使ったMutexの実装だが、RP2040の場合はデュアルコアなので、使えない。
MutexとRwLock
Mutexの場合はlock()でロックを取得するとRead,Writeが可能になる。RwLockの場合、Readするためのロックを取得するread()とWriteするためのロックを取得するwrite()がある。
実装例
AtomicBoolが使える場合の簡単な実装例は次のとおり。
Mutex<T>に対してMutexGuard<T>が定義される。Mutex::lock()はMutexGuard<T>を返す。- この返り値が生存している間はロックされている。
MutexGuard<T>はDeref,DerefMutを実装しているので、透過的にTと同様に扱える。MutexGuard<T>がDropしたときにアンロックされる。Mutex<T>は、ロック変数(locked: AtomicBool)とデータが格納される変数(data: UnsafeCell<T>)からなる構造体。UnsafeCellに入っているので、Mutex変数自体がmutでなくても、中身は変更できる。UnsafeCellの操作はunsafe
- ロック変数は、
compare_exchangeでアトミックにロックする。 Mutex::unlock()はMutexGuard<T>のDropで自動的に呼ばれ、手動では呼ばれないのでpubは不要。- Mutexを使う目的は複数のスレッドから安全に変数にアクセスすること。そのために必要な
Sync,Sendトレイトを付けておく。これらはコンパイラによる自動判断ではなく、ライブラリの実装者がコンパイラに約束することなのでunsafe。unsafe impl<T> Sync for Mutex<T> {}unsafe impl<T> Sync for MutexGuard<'_, T> where T: Sync {}unsafe impl<T> Send for MutexGuard<'_, T> where T: Send {}
use core::cell::UnsafeCell; // 内部可変性のため
use core::ops::{Deref, DerefMut};
use core::sync::atomic::{self, AtomicBool};
// Mutex::lock()はMutexGuard<T>を返す
pub struct MutexGuard<'a, T> {
lock: &'a Mutex<T>,
}
impl<'a, T> MutexGuard<'a, T> {
fn new(lock: &'a Mutex<T>) -> Self {
MutexGuard { lock }
}
}
// MutexGuard<T>は`Deref`, `DerefMut`を実装しているので透過的に`T`とアクセスできる
impl<T> Deref for MutexGuard<'_, T> {
type Target = T;
fn deref(&self) -> &T {
unsafe { &*self.lock.data.get() }
}
}
impl<T> DerefMut for MutexGuard<'_, T> {
fn deref_mut(&mut self) -> &mut T {
unsafe { &mut *self.lock.data.get() }
}
}
// MutexGuard<T>は`Drop`されるとロックを解除する
impl<T> Drop for MutexGuard<'_, T> {
fn drop(&mut self) {
self.lock.unlock();
}
}
pub struct Mutex<T> {
locked: AtomicBool,
data: UnsafeCell<T>,
}
impl<T> Mutex<T> {
pub const fn new(value: T) -> Self {
Self {
locked: AtomicBool::new(false),
data: UnsafeCell::new(value),
}
}
pub fn lock(&self) -> MutexGuard<'_, T> {
while self.locked.compare_exchange(false, true, Ordering::Acqire, Ordering::Relaxed).is_err(){
// 他のスレッドがlockedを開放するまで待つ
}
MutexGuard::new(self)
}
fn unlock(&self) {
self.locked.store(false, atomic::Ordering::Release);
}
}
unsafe impl<T> Sync for Mutex<T> {}
unsafe impl<T> Sync for MutexGuard<'_, T> where T: Sync {}
unsafe impl<T> Send for MutexGuard<'_, T> where T: Send {}
グローバル・アロケータとallocクレート
タスク構造体やリンクリストのノードをヒープに割り当てるためにグローバルアロケータを実装する。ここでは、一番簡単な実装として、Bump Pointer Allocを用いる。領域を割り当てるときにポインタが前進(Bump)するだけ。領域を開放してもヒープには戻らない。
グローバルアロケータが存在すると、no_std環境でも、coreクレートに加えてallocクレートが使え、BoxやVecなどが使える。
BumpPointerAllocという構造体が、ヒープ全体を管理する。ヒープの先頭とサイズの2つのメンバを持つ。- ヒープの先頭とサイズは、メモリマップを考慮して、即値で指定する。
alloc()は、アライメントに注意して、割り当てる領域の先頭のポインタを返し、未割り当て領域のポインタを進める。- 作成したアロケータを
Mutexで囲って、それを#[global_allocator]に指定する。
// Bump pointer allocator implementation
// ポインタを増加するだけのアロケータ実装
use crate::mutex::Mutex;
use core::alloc::{GlobalAlloc, Layout};
use core::cell::UnsafeCell;
use core::ptr::{self};
struct BumpPointerAlloc {
head: UnsafeCell<usize>,
end: usize,
}
// 使っていないSRAM領域中に、ヒープ領域を即値で定義する。
// この領域が他に使われないことはプログラマが保証しなければならない。
const HEAD_ADDR: usize = 0x2001_0000;
const HEAP_SIZE: usize = 1024;
unsafe impl Sync for BumpPointerAlloc {}
impl BumpPointerAlloc {
const fn new() -> Self {
Self {
head: UnsafeCell::new(HEAD_ADDR),
end: HEAD_ADDR + HEAP_SIZE,
}
}
unsafe fn alloc(&self, layout: Layout) -> *mut u8 {
let head = self.head.get();
let size = layout.size();
let align = layout.align();
let align_mask = !(align - 1);
// move start up to the next alignment boundary
let start = (*head + align - 1) & align_mask;
if start + size > self.end {
// a null pointer signal an Out Of Memory condition
ptr::null_mut()
} else {
*head = start + size;
start as *mut u8
}
}
unsafe fn dealloc(&self, _: *mut u8, _: Layout) {
// this allocator never deallocates memory
}
}
unsafe impl GlobalAlloc for Mutex<BumpPointerAlloc> {
unsafe fn alloc(&self, layout: Layout) -> *mut u8 {
self.lock().alloc(layout)
}
unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout) {
self.lock().dealloc(ptr, layout);
}
}
// グローバルメモリアロケータの宣言
#[global_allocator]
static HEAP: Mutex<BumpPointerAlloc> = Mutex::new(BumpPointerAlloc::new());
領域を開放したらヒープに回収されたい場合、リンクリストなどを使って空き領域を管理する方法が知られている。ただし、これも、細切れになった領域をマージしていかないと、結局、割り当てることができなくなってしまう。
実用的なアロケータの設計は難しく、Cの標準のmallocに対してより効率的な代替アロケータが提案されている。それらはLD_PRELOADやダイナミックリンクのしくみを使って、標準のmalloc()を置き換えることで利用する。
alloc::boxed::Box, Box::leak()
ヒープ上にBoxを使って変数を割り当てた場合でも、Rustではライフタイムの制約を受ける。つまり、束縛されていた変数がスコープを抜けるとDropされて割り当てられたメモリが開放される。
そうしたくない場合は、Box::leak()を使って開放されないようにする。Box::leak()を適用した場合、そのメモリ領域のライフタイムは'staticとなり、'staticな変数に代入することが可能となる。
SysTickハンドラ
Cortex-Mコアは、コアペリフェラルとしてSysTickというタイマをもっており、RTOSなどの基本タイマとして使われる。
SysTick割り込みを設定する。
SysTik割り込みは通常の割り込みではなく例外として処理される。
systick.rs(要点)
- Count型を定義し、
incr()によって、外部に所有権を取得することなく、wrapping_add()を内部演算で処理する。Mutexの実装であるUnsafeCellの内部可変性を利用している。- Rustでの通常の加算は、デバッグビルドではオーバーフローチェックが入るが、リリースビルドではオーバーフローチェックが入らない。意図的にオーバーフローチェックをしない場合は
wrapping_add()を使う。
init()はSysTickの設定に使われるレジスタ類をまとめたSYST構造体の可変参照である&mut SYSTとリロードカウンタの値を引数で取る。SYSTはここに所有権をmoveするので他では使えなくなる(同じくSYSTを使っているcortex_m::delay::Delayは同時には使えない)。
static変数としてSYSTICK_COUNTを用意し、Mutex経由でアクセスする。SYSTICK_COUNTの値を操作するときはlock()を取る→MutexGuardが帰る→Derefにより透過的に中身にアクセスできる。- スコープが外れれば、ロックはドロップされる。
SYSTICK_COUNTの値は外部で読めるようにする。- オブジェクト経由のアクセスではなく、
systick::count_get()関数を呼ぶ。Rustらしくないが、こうするのが所有権問題を簡単に解決できる。
- オブジェクト経由のアクセスではなく、
- 例外ハンドラでは
SYSTICK_COUNTをインクリメントし、PendSVを呼ぶ(タスクスイッチが強制的に発生する)。
struct Count(u32);
impl Count {
const fn new(value: u32) -> Self {
Self(value)
}
fn incr(&mut self) {
self.0 = self.0.wrapping_add(1);
}
}
// Mutex::new, Count::new が const fn なので、static変数を初期化できる
static SYSTICK_COUNT: Mutex<Count> = Mutex::new(Count::new(0));
pub fn init(syst: &mut cortex_m::peripheral::SYST, reload: u32) {
syst.set_clock_source(SystClkSource::Core);
syst.set_reload(reload);
syst.clear_current();
syst.enable_counter();
syst.enable_interrupt();
}
fn count_incr() {
// lockを取って、UnsafeCell<>の中の値を操作する(mutでなくてもOK:内部可変性)
SYSTICK_COUNT.lock().incr();
}
pub fn count_get() -> u32 {
SYSTICK_COUNT.lock().0
}
#[exception]
fn SysTick() {
info!("SysTick:{}", systick::count_get());
systick::count_incr();
SCB::set_pendsv();
}
呼び出し側
let mut pac = pac::Peripherals::take().unwrap(); // pacの取得
let mut core = pac::CorePeripherals::take().unwrap(); // coreの取得
let mut watchdog = Watchdog::new(pac.WATCHDOG); // watchdogの初期化
let external_xtal_freq_hz = 12_000_000u32; // RasPicoでは12MHzの外部クロックが接続されている
let clocks = init_clocks_and_plls( // 内部クロックの初期化(デフォルトでは125MHz)
external_xtal_freq_hz,
pac.XOSC,
pac.CLOCKS,
pac.PLL_SYS,
pac.PLL_USB,
&mut pac.RESETS,
&mut watchdog,
)
.ok()
.unwrap();
// コアクロックの周波数を確認
info!("system clock = {}", clocks.system_clock.freq().to_kHz()); // 125000kHz = 125MHz
// コア周波数が125MHzなので
// リロード値を 125_000にしたら 1kHzでSysTickが割り込む。
// リロード値を 125_000 * 100 にしたら 100msでSysTickが割り込む。
// リロード値の最大は 0xff_ffff(24bit)=16_777_215=125_000*134.21772(ms)が最も遅い設定
systick::init(&mut core.SYST, clocks.system_clock.freq().to_kHz() * 100); // SysTick = 100ms
デバイスドライバ
SysTickに限らず、GPIOなど、MCUは多くのペリフェラルを提供する。一般に、それらはレジスタに対するアクセスで、CMSISで定義され、チップメーカからはSVD(System View Description)という形で公開される。svd2rstというツールを使えばrustの雛形が生成される。
cortex_mの枠組みでは、それらはPAC(Peripheral Access Crate)として実装される。そして、RAII(Resource Acquisition Is Initialization)の考え方から、初期化時に所有権が取得され、変数に束縛される。
ペリフェラル、たとえばLEDなどは、それぞれのタスクからアクセスしたいが、mainで初期化すると、そのスコープに所有権が取られる。
- 解決策1。ペリフェラルや環境全体を表す構造体を作成し、そこから呼び出される関数に
&mutとして、引数で渡して引き継いでいく、という方法がある。しかし、複数のタスクが非同期に呼び出されるRTOSの環境では難しい。 - 解決策2。ペリフェラルはカーネルが初期化し、カーネルが所有する。タスク側からはシステムコールを通じてペリフェラルにアクセスする。このデバイスドライバはカーネルモードで実行される。一般的なOSの役割としてハードウエアを抽象化して管理する、というものがあり、通常のOS的な考え方だが、RTOSとしてはオーバヘッドが大きい。
- 解決策3。複数のタスクからペリフェラルにアクセスできるライブラリとしてRTOSがデバイスドライバを提供する。複数タスク間でのリソース共有はデバイスドライバが吸収する。この場合、デバイスドライバはタスクのコンテクストで実行され、タスク切換えが発生しない。
ここでは3つめの方法を選択する。
リソースの共有方法
本来的な性質としてペリフェラルはstatic mutとなるが、Rustでは制限が非常に厳しい。それを回避する方法として、MutexとOptionでくるむ。
- 構造体自体は
staticとなる。表面上はmutではないが、Mutex(の中のUnsafeCell)によって内部可変となる。 - 共有リソースへのアクセスを排他制御するために
Mutexで囲む。 static変数のデフォルトの初期化が行われるが、それはconst fnでなければならない。とりあえずOptionでくるみNoneで初期化しておく。- 実際の初期化時に
init()を呼び、ペリフェラルの設定と初期化を行なう。デバイスリソースをcortex_mの流儀で確保&初期化し、それをinit()に渡して、Mutexの中身をreplace()で置き換える(代入ではなく内部可変の操作を行う)。 lazy-staticも同様の目的を行うためのクレートだし、OnceCellもそのためのモノだが、Cortex-M0+のアトミック操作の制限のために、今回はそれらが使えないので自前で実装する。
https://tomoyuki-nakabayashi.github.io/book/concurrency/index.htmlこちらでは実行時チェックのためRefCellを重ねている。RefCellはアトミック演算を使っているのでCortex-M0+では使えない。Mutexが実装に用いているUnsafeCellを信用することにする。また、Mutexの実装にcortex_m::interrupt::Mutexを使っているが、RP2040ではマルチコアのために、使えない。ただし、基本的な考え方は同じである。
use embedded_hal::digital::{OutputPin, StatefulOutputPin};
use rp2040_hal::gpio::{bank0::Gpio25, FunctionSio, Pin, PullDown, SioOutput};
use crate::mutex::Mutex;
static LED: Mutex<Option<Pin<Gpio25, FunctionSio<SioOutput>, PullDown>>> = Mutex::new(None);
pub fn init(pin: Pin<Gpio25, FunctionSio<SioOutput>, PullDown>) {
LED.lock().replace(pin);
}
pub fn set_output(pin: bool) {
if pin {
let _ = LED.lock().as_mut().unwrap().set_high();
} else {
let _ = LED.lock().as_mut().unwrap().set_low();
}
}
pub fn toggle() {
let _ = LED.lock().as_mut().unwrap().toggle();
}
カーネルの先頭で初期化
led::init(pins.gpio25.into_push_pull_output());
アプリの中から呼ぶとき
led::toggle();
gdbの使い方
RTOSではアセンブラレベルで命令を実行し、CPUのレジスタを直接操作する。GDBでのステップ実行による解析がデバッグには必須。
以前に自分で書いたメモも非常に役にたった。今回も、あらためて使い方メモをまとめておく。きっと何年かあとの自分の役に立つだろう。
参考文献
- Rustで始める自作組み込みOS入門
- 詳解 Rustアトミック操作とロック
- インターフェイス 2024年11月 ゼロから作るマルチコアOS
- Procedure Call Standard for Arm Architecture (AAPCS)
- ARM®v6-M Architecture Reference Manual
- Cortex-M0+ Technical Reference Manual
- ARM® Cortex®-M mbed™ SDK and HDK deep-dive
- ARM Cortex-M RTOS Context Switching
- FreeRTOS(Cortex-M)のコンテキストスイッチ周りを調べてみた
- rp2040のPendSVでコンテキストスイッチをしよう
- ARM関連(cortex-Mシリーズ)のCPUメモ
- ARM Cortex-M 32ビットマイコンでベアメタル “Safe” Rust
- Cortex-M0+ CPU Core and ARM Instruction Set Architecture